The Indexing API is an interface that allows you to notify Google of changes related to URLs on a website. These changes include:
- Adding a URL to the Google index,
- Updating a URL (technically, re-indexing),
- Removing a URL from the Google index,
- Obtaining the status of the last request.
Table of contents
- The Indexing API is not used for indexing
- Minimum Value to Index
- Advantages and disadvantages of Indexing API
- Advantages
- Disadvantages
- Indexing API is not only for JobPosting and Broadcast Event
- Why does Indexing API work for other types of content?
- Indexing API vs. XML Sitemap
- Portals with Linkhouse’s Indexing API
- Indexing API – what is it used for?
- Content Re-Indexing
- Removing a URL from the index
- Faster verification of critical issues with Google Search Console
- Accelerating URL crawling
- Tools for Indexing API
- Research: Does Indexing API affect the Crawl Budget?
- Research 1
- Research 2
- Research 3
- Conclusions
- How to bypass the 200 request limit per day?
- In summary, Indexing API is a Crawling API
The Indexing API is not used for indexing
Despite its name, Indexing API is not responsible for adding a URL to the index. According to the documentation, it is for crawling, not indexing.
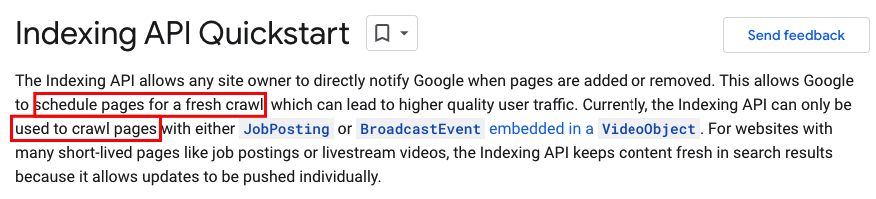
Request Index (sending the information to Google) is used to crawl/scan the URL immediately and shown in the Crawler section on the chart below.
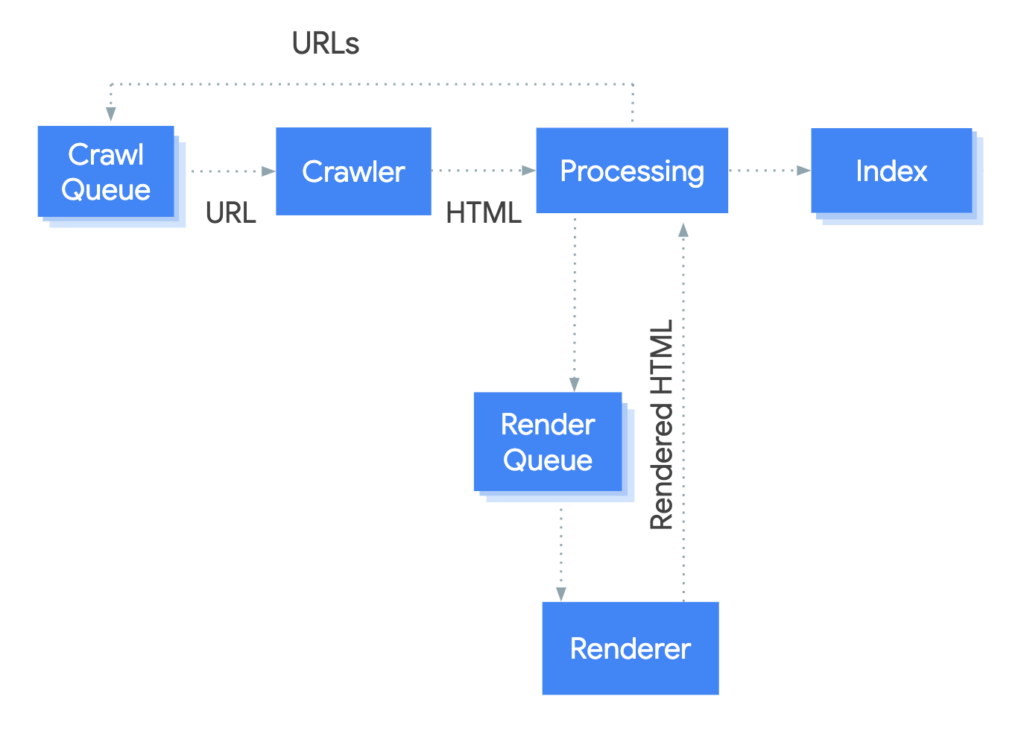
In the Request Index, the crawling queue is skipped and after scanning, Googlebot proceeds to process the URL (shown in the Processing section on the chart). After processing, which usually takes from 4-6 hours up to 24 hours, Google decides whether to add the URL to the index. If the URL does not meet all the requirements, Googlebot can decide not to index it. Our specialist Sebastian Heymann defines these requirements as the MVI – Minimum Value to Index.
Indexing API Request is an immediate scan of the URL and processing, and not adding the URL to the index as it’s commonly believed. |
Although the documentation states that it is planning pages to crawl, we have tested it on thousands of cases and have confirmed that it works almost immediately. The maximum delay we obtained during scanning was a dozen seconds.
Minimum Value to Index
A theory called Minimum Value to Index (MVI) says how much reputation an URL address needs to get to be added to the index.
This reputation is divided into on-site and off-site factors.
On-URL factors include all elements indexed under a specific URL address:
- website menu and footer;
- the main content of the site;
- other indexed content (cookie information, forms, image alts);
- Page Experience factors, such as:
- Core Web Vitals;
- HTTPS;
- mobility;
- no interrupting ads;
- url response time -> Time to First Byte (TTFB).
Off-URL factors include all elements not directly related to indexing a specific URL address:
- external links
- internal links
- duplicated URL addresses within the website
- duplicated URL addresses outside the website
- domain value
Google will add such a URL address to the index when it receives an appropriate value based on the above factors.
If you have already sent a Request Index multiple times and the URL address is still not indexed, then look for the reasons in the factors mentioned above. |
Advantages and disadvantages of Indexing API
Advantages | Disadvantages |
Bypassing the crawling queue | Only 200 requests per project per day on Google Cloud |
Real-time processing | Maximum of 100 requests in a row |
Speeds up SEO work on the website | Daily limit according to US Eastern Time (GMT-4) |
Works not only for JobPosting and Broadcast Event | Only for verified domains in GSC |
Separate interface | Does not affect the crawl budget of the website |
Fastest way of indexing pages |
Indexing API is not only for JobPosting and Broadcast Event
Although the documentation indicates that the tool is only intended for job offers and pages with video broadcasts, it actually works for other types of pages. However, John Mueller from Google stated on Twitter that the Indexing API is only designed to work for JobPosting and Broadcast Event pages, and that any other types of content will be ignored.
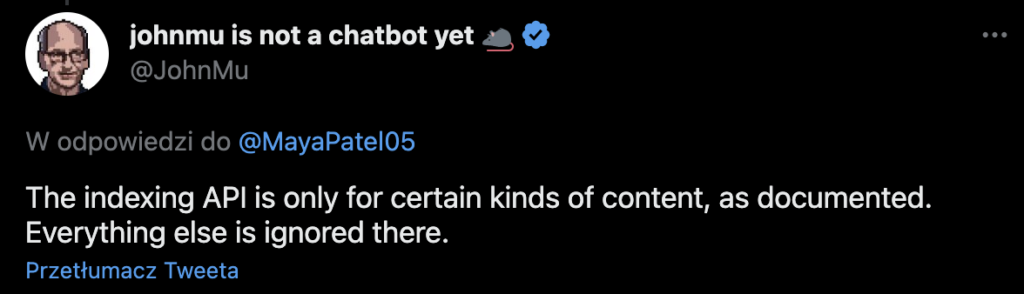
When John Mueller was asked what would happen if someone tried to use the Indexing API for a different type of content, he said that it wouldn’t help with indexing other types of content.

Fortunately, someone asked if there would be any penalty for trying to use the Indexing API for other types of content and John responded that there wouldn’t be any penalty.

Why does the Indexing API work for other types of content?
Googlebots are unable to determine what is on a given page until they visit it. There is no way to check if the HTML code contains JobPosting or Broadcast Event unless the URL has been scanned/crawled before.
This could be useful when removing URLs (because such a URL must be known beforehand), but in our tests, we found that we can safely remove URLs from the index that are not related to the aforementioned content.
We believe that this interface is a replacement for what any user can do in their Google Search Console by clicking on Request Index for a URL. You don’t need to launch the Google Search Console interface and download the URL beforehand, which saves Google resources.

Indexing API instead of Request Indexing in Google Search Console.
In Google Search Console you can download up to a few URLs daily, while in Indexing API – 200.
Indexing API vs XML Sitemap
Below you will find a table with information on the differences between sitemaps and Indexing API.
Indexing API | Sitemap.xml |
Real-time assurance of URL being crawled | No assurance of URL being crawled, even in the future |
You know when URL will be crawled | Don’t know when URL will be crawled |
Separate interface | Can be added through Google Search Console or robots.txt file |
Request data always available in Google Search Console | Request data not always available in Google Search Console |
Limit of 200 requests per day | Large sitemaps provide more than 200 requests per day |
Number of requests not dependent on crawl budget | Number of requests dependent on crawl budget. |
The above elements are processed differently, so remember that when using them.
Planning to add URLs to the Indexing API instead of adding them to the sitemap at the beginning can help with more optimal crawling of new URLs. |
Portals with Indexing API integrated in Linkhouse
The level of indexing for portals using Indexing API is almost 100%. Occasionally, some URLs may not be indexed due to indexing of another URL, incorrect URL provided, or temporary issues with access to the publisher’s site.
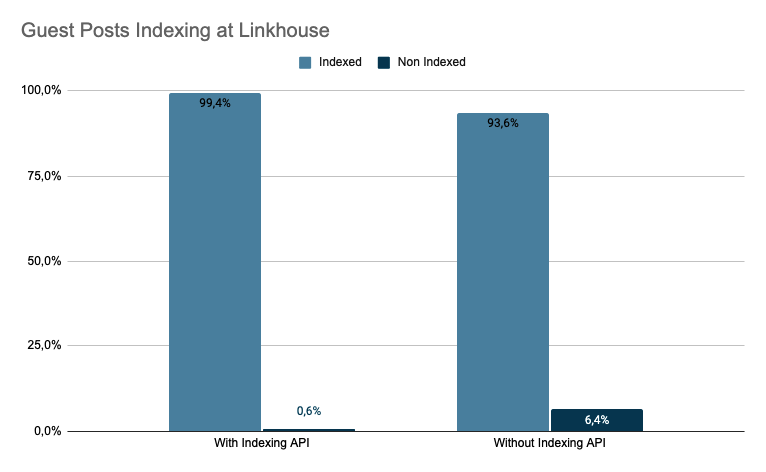
If you are a publisher, remember that the most important thing for the advertiser is to be sure that the articles they have purchased are to be indexed.
If you are an advertiser, remember that you can choose the portals that have been added to the Google Indexing API application in Linkhouse, while having almost 100% certainty that your article will be added to the index.
Indexing API – What is it used for?
What can Indexing API be used for besides crawling and indexing URLs? Below is a list of possibilities that will help you understand why you should support your SEO efforts with Indexing API from today.
Content re-indexing
Whenever you are working on some content, optimizing it, making changes or removing outdated parts, you can speed up the reindexing process of that content by sending a Request Index to that URL. This will help you achieve faster reindexing.
You don’t have to wait for the URL to be scanned from the crawling queue – you never know when a particular address will be scanned.
Removing URL address from index
With the Indexing API, you can remove outdated URLs from the index using URL_deleted or URL_updated.
Use URL_deleted when you have removed a URL and there is nothing on it anymore – it returns HTTP code 404.
Use URL_updated to remove a URL from the index when it still exists but you don’t want it to be indexed by Google and have marked it as not indexable in the <head> tag using meta robots=noindex, but it returns HTTP code 200.
Faster verification of critical issues with Google Search Console
Many specialists use the “validate fix” button to fix pages that are not indexed in Google Search Console. It is then rejected because not all the URLs in the report have been fixed, only some of them. If not all URLs have been fixed, instead of using “validate fix”, add those URLs to the Indexing API. Critical issues worth addressing include:
– server error,
– redirect error,
– duplicate content, user did not indicate canonical page.
Accelerating URL crawling
Do you see a lot of URLs in the “Page detected – currently not indexed” report? Here, Google hasn’t yet looked at a URL, but it’s in the queue to be crawled. With the help of the Indexing API, you can speed up the crawling of these addresses without worrying about the fact that they are likely far down in the crawl queue.
Are there any addresses critical from a business perspective? Go get to work!
Tools for API Indexing
If the above article has convinced you to use the Indexing API, you can implement such an application on your desktop. You can find ready-made codes and instructions in the following links:
– https://github.com/m3m3nto/giaa (Memento from Rome)
– https://github.com/marekfoltanski/indexingapi (Marek from Poland)
Research: Does Indexing API affect Crawl Budget?
Research 1
Input data:
– Stable website with a constant amount of crawling pages with HTTP code 200.
– Several dozen requests per day to the same addresses on some days.
– I only requested the URLs that were in the index.

The scanning trend line was slightly decreasing.
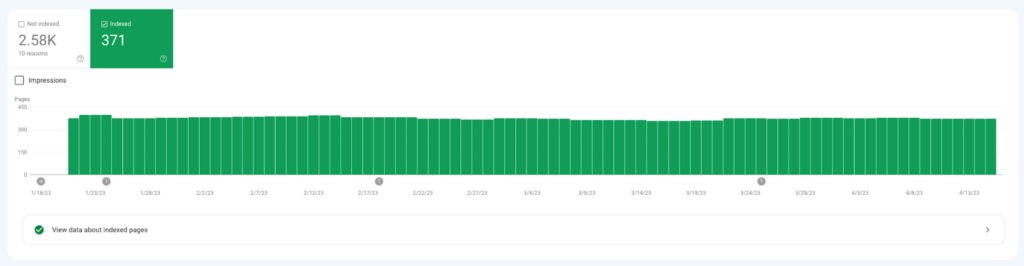
The number of indexed URLs remains constant.
Result: no impact of Indexing API on the crawl budget of the website. There is no positive or negative impact on the crawl budget. It seems that Indexing API is just an addition to the current Crawl Budget.
Research 2
Input data:
– Stable website with a constant amount of crawled pages with HTTP 200 status code.
– Requests to URLs that already return 404.
– Only downloading URLs that are indexed by Google.
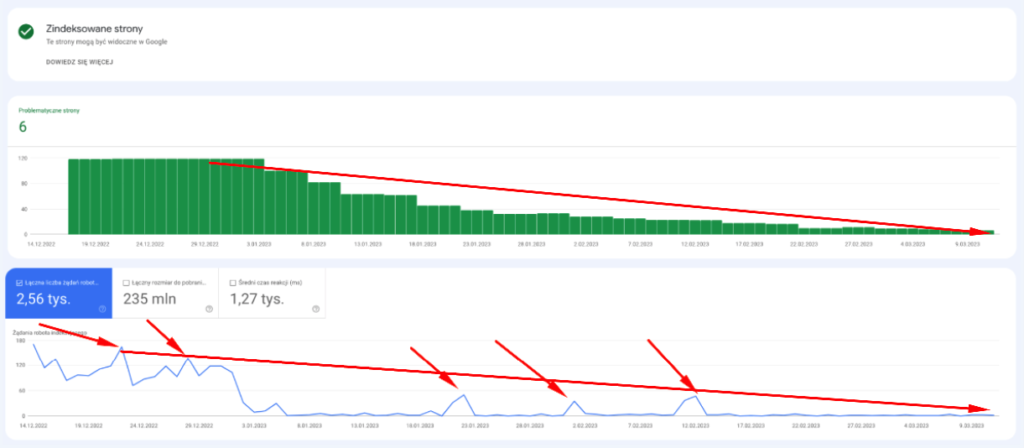
Result: the decrease in crawling is not due to indexing API requests, but rather due to the number of URLs in the index.
Research 3
Input data:
– Stable website with a constant amount of crawled pages with HTTP 200 code.
– Requests only to URLs that have HTTP 200 code.
– Requests to URLs that were previously in the index and those that were not in the index.
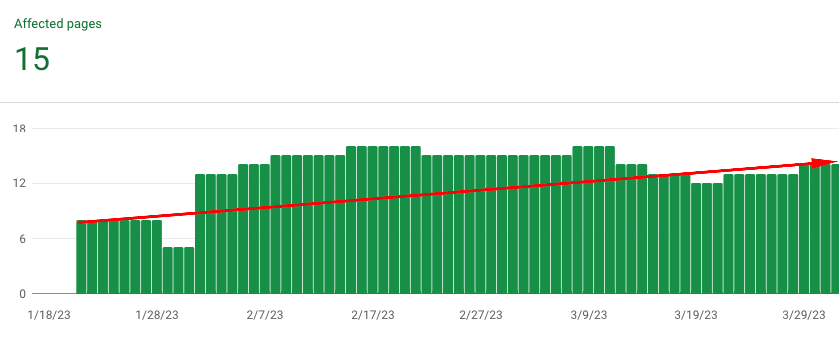
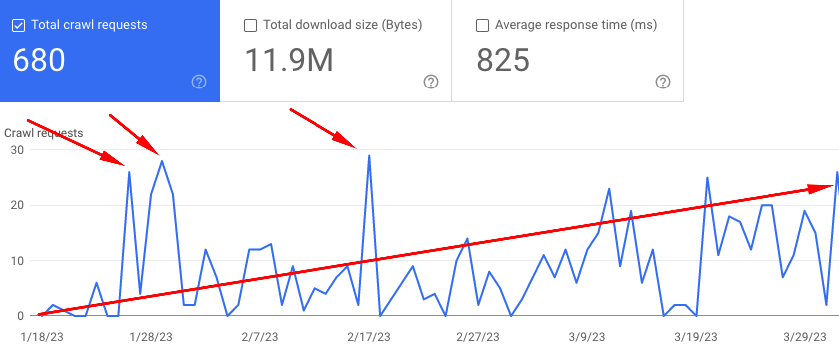
Result: After three attempts with the Indexing API and indexing new URLs, the average crawl budget of the website increased.
Conclusions
Indexing API removes URLs from the crawling queue.
Indexing API does not use the website’s current Crawl Budget.
Crawling by Indexing API itself does not cause an increase or decrease in Crawl Budget.
Crawl Budget depends on the number of URLs in the index.
Indexing API may indirectly affect Crawl Budget
by adding/removing URLs from the index
removes URLs from the crawling queue.
How to bypass the limit of 200 requests per day?
The limit currently applies to one project per email address. If you create 10 projects, you can use 2000 requests per day and expand this by using more email addresses.
Remember that you must be a verified owner of the website in Google Search Console in order to send requests to the same website from another Google account.
In summary, the Indexing API is a Crawling API
As mentioned earlier, the Indexing API is actually a Crawling API with the ability to remove a URL from the index and retrieve current information about URLs. The address will be indexed only when it reaches the appropriate value for indexing – Minimum Value to Index.
We do recommend using the Indexing API while it works for any URL. As soon as it starts working for JobPosting and Broadcast Event only, we will have to rely on indexers.

Author
Sebastian Heymann – SEO in his life has existed since 2011. Co-creator of the Link Planner tool. Creator of the only SEO training on the use of Google Search Console. He enjoys challenging, questioning, testing, and creating public debates. He’s really into search engine optimization and analyzing data, and he’s always eager to pass them along to others.